
B2B Insights
May 29, 2026

Data quality issues cost organizations between $12.9 million and $15 million annually, according to Gartner research. 82% of organizations spend at least one full day each week fixing master data issues, while 66% rely on manual reviews to monitor data quality. The most common data quality issues include inaccurate data, incomplete data, duplicate records, inconsistent formats, outdated data, and human error. Additional data quality problems include data silos, validation failures, schema drift, ambiguous data, hidden and dark data, poor data governance, and lack of data integrity. Poor data quality spreads across sales, marketing, reporting, forecasting and AI workflows, creating friction at every GTM stage.
Sales teams waste capacity pursuing low-fit accounts, marketing teams build segments that do not reflect the market, and RevOps teams produce forecasts based on unreliable inputs. When B2B data quality suffers, AI-driven workflows produce unreliable outputs faster and at greater scale, causing hallucinated personalization, misaligned lead scoring, and flawed forecasting. Solutions include defining clear data standards and ownership, implementing automated validation rules, conducting regular data cleansing and enrichment, establishing data quality dashboards, standardizing data entry processes, integrating data sources, centralizing GTM data, training employees on data standards, and implementing continuous monitoring. Organizations can see early improvements within weeks through quick fixes like deduplication and validation, though long-term results typically take 6-12 months.
Your CRM shows 10,000 contacts. Marketing built a campaign targeting 3,000 of them. Sales attempted outreach to 500. Only 47 answered the phone.
The problem is not call reluctance or bad timing. Gartner research estimates the annual financial impact of poor data quality at $12.9 million to $15 million per organization. 82% of organizations spend at least one full day each week fixing master data issues.
Here are the 13 most common data quality issues and how to solve them.
Data quality issues occur when information is inaccurate, incomplete, inconsistent, outdated, or duplicated. These problems undermine data reliability and the decisions made from it.
Data quality is the degree to which your go-to-market engine can act on what it knows. In a revenue context, technical completeness matters only if it helps B2B sales and marketing teams reach the right people, at the right companies, with the right message, and at scale.
A technically complete CRM record is still a liability if the contact changed roles, the company no longer fits your ICP, or the account data cannot support a qualified commercial conversation.
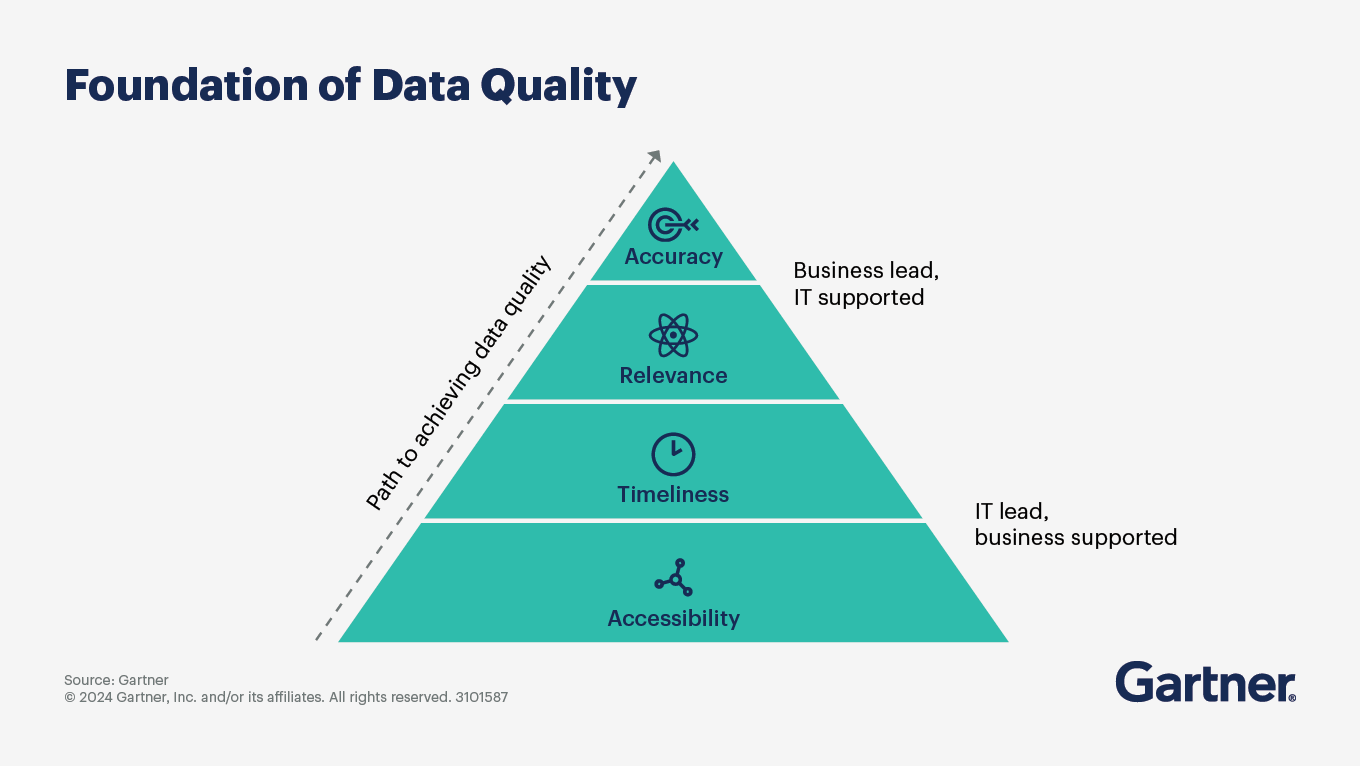
Understanding how healthy your B2B data is starts with a clear way to evaluate it. Five dimensions matter most:
Accuracy: Is the data correct right now? A contact record with a bounced email address, an incorrect phone number or an outdated job title is an accuracy failure.
Completeness: Are required fields populated? A record may be technically accurate but still commercially weak if it's missing key information such as job function, company size, industry, location, or direct contact details.
Consistency: Does the same data tell the same story across systems? If your CRM lists "International Business Machines" while your marketing automation platform records "IBM," reporting becomes harder to trust.
Timeliness: Is the data current enough to support action? B2B data changes constantly as people move roles, companies restructure, teams expand into new markets, and contact details decay.
Validity: Does data follow required formats, rules and standards? An email address without an "@" symbol, a phone number with missing digits, or an invalid country code are all validity failures.
| Data Quality Issue | Common Causes | Business Impact | Solution |
|---|---|---|---|
| Inaccurate data | Human error, outdated systems, unverified inputs | Misreporting, wrong insights, failed outreach | Verification tools, validation rules, cross-referencing |
| Incomplete data | Optional fields left blank, poor form design, data migration issues | Inability to segment, inaccurate targeting, compliance gaps | Mandatory fields, real-time validation, enrichment APIs |
| Duplicate records | Lack of unique identifiers, inconsistent entry conventions, merging data sources | Inflated KPIs, wasted resources, confused communications | De-duplication scripts, fuzzy matching, canonical ID assignment |
| Inconsistent formats | No standardization, multiple data sources, user-generated input | Errors in sorting/filtering, broken analytics pipelines, inefficient operations | Define format rules, standardization tools, schema validators |
| Outdated data | Lack of update triggers, manual sync processes, infrequent refresh cycles | Wrong outreach, incorrect reporting, regulatory risk | Regular refresh cycles, external validation APIs, real-time validation |
| Human error | Typos, copy-paste errors, misunderstanding field intent | Costs $150,000-$600,000 annually, mismatched records, failed automation | UI enhancements, user training, audit logs |
| Data silos | Departmental tools, legacy systems, no central data architecture | Incomplete insights, manual workarounds, poor collaboration | Data integration platforms, centralized data lake |
| Validation failures | Weak validation logic, inconsistent rule enforcement | Corrupt records, failed workflows, unreliable dashboards | Schema constraints, real-time validation, alert systems |
| Schema drift | Unannounced API updates, pipeline modifications without documentation | ETL failures, broken reports 1. Inaccurate DataInaccurate data refers to information that is incorrect or does not align with reality. This includes errors during data entry, discrepancies between systems, or outdated records no longer reflecting current state. Common causes include human error during manual entry, outdated systems holding old or incomplete information, and unverified inputs entered without confirmation. Example: Customer address listed as "123 Lame St" instead of "123 Lane St" causes delivery service to fail in reaching customer, leading to dissatisfaction and wasted resources. Business impact: Unreliable data leads to incorrect reports and poor decision-making affecting sales forecasts and financial planning. Sales teams reach out to the wrong people, marketing teams personalize campaigns using false assumptions, and RevOps teams report on activity that does not reflect the real market. Solution: Implement verification tools that cross-check incoming data against trusted databases. Create strict validation rules to check for discrepancies at point of entry. Validate data by comparing with trusted sources like LinkedIn or Clearbit. 2. Incomplete Data Incomplete data refers to missing essential information or attributes necessary for analysis, reporting, or decision-making. Key fields are left blank, not captured, or overlooked during data entry or processing. A record may be technically accurate but still commercially weak if it is missing key information such as job function, company size, industry, location, seniority, buying committee role or direct contact details. Example: CRM entry missing contact number or email prevents sales teams from reaching out to customers or prospects, meaning lost sales opportunities or inability to follow up on leads. Business impact: Missing data points prevent accurate audience segmentation and affect targeted marketing. Missing details lead to ineffective marketing and wasted spend. Missing fields weaken segmentation, routing and reporting. Solution: Design forms and databases to make key fields mandatory, ensuring essential information is captured before submission. Implement real-time validation to notify users when they have skipped essential fields. Use third-party enrichment APIs to fill in missing information. 3. Duplicate RecordsDuplicate records occur when the same entity is entered multiple times in a database or system, often with slight variations in the data. This results in redundant data causing confusion, inaccuracies, and inefficiencies. Common causes include lack of unique identifiers (without unique IDs or primary keys, same entity may be recorded multiple times), inconsistent entry conventions (users enter same information in varying formats), and merging of data sources during system migrations. Example: Two records for "John Smith," one with "John A. Smith" and another with "John Smith." Marketing might target him multiple times while sales reps waste time reaching out to duplicate profiles. Business impact: Duplicates create noise, inflate database size, distort attribution, confuse ownership and cause multiple teams to contact the same person or company. They weaken reporting because activity and engagement can be split across several records. Solution: Automate de-duplication processes using scripts to merge duplicate records based on matching or fuzzy identifiers. Use fuzzy matching algorithms to detect minor variations. Assign unique ID to each entity to link all records under one primary ID. 4. Inconsistent FormatsInconsistent formats occur when data is represented in different structures, units, or notations across systems or datasets. This lack of uniformity causes issues with data integration, sorting, analysis, and reporting. Many organizations lack clear standards for data formatting, leading to mixed formats for similar data points (dates, currencies, phone numbers). When users input data manually, they may use varying formats based on preferences or regional conventions. Example: Dates recorded as "MM/DD/YYYY" in one system and "DD-MM-YY" in another. This inconsistency prevents data from being sorted chronologically and could result in misinterpretations of time-sensitive information. Business impact: Inconsistent formats cause issues when sorting or filtering data, especially if certain formats are not recognized correctly by databases or reporting tools. Teams spend extra time cleaning and reformatting data, diverting resources from more critical tasks. Solution: Set clear, organization-wide rules for data formatting (date format, phone number structure, currency symbols) and ensure uniform adherence. Use tools like DataRobot or Alteryx to automate conversion of data into standardized format before analysis. 5. Outdated DataOutdated data refers to information that has changed over time but has not been updated in your system. This could be outdated customer information, old product details, or anything that has changed but was not captured in timely manner. B2B data changes constantly: People move roles, companies restructure, teams expand into new markets, and contact details decay. A record that was accurate six months ago may now be misleading. Example: Email sent to former employee who no longer works at company. This common mistake happens if employee's data has not been updated or deleted from CRM, resulting in misdirected communication and poor customer experience. Business impact: Outdated contact details lead to misdirected communications, missed opportunities, and damaged customer relationships. Outdated data distorts reports, leading to inaccurate decision-making and poor strategic planning. Solution: Set automatic refresh intervals (monthly or quarterly) to keep data current. Leverage third-party APIs like LinkedIn, Clearbit, or Experian to validate and update data in real-time. Use automated systems to validate and update information as it is entered. 6. Human ErrorHuman error is the hands-down most common source of data quality issues. Human-caused errors related to entry, processing, and handling of data have major impacts on organizational data quality. Common causes include typos (simple typing mistakes), copy-paste errors (copying data from one system to another), and misunderstanding field intent (data entry staff misinterpreting purpose of a field). Example: Misspelled customer name, such as "Jonh Smith" instead of "John Smith," can confuse customer service systems, leading to poor experiences and delays in addressing issues. Business impact: Human error is attributed to 1-4% of total data quality costs, meaning these errs may cost organizations $150,000-$600,000 every single year. Incorrect data entry causes records to be misaligned and can cause automated systems to malfunction. Solution: Implement user-friendly input forms with dropdowns, auto-complete features, and real-time validation to reduce human error. Provide comprehensive training to data entry teams to ensure they understand field requirements and importance of accuracy. 7. Data SilosData silos occur when information is stored in isolated systems that do not communicate with each other. These silos prevent seamless data sharing across teams, making it difficult to get comprehensive view of business operations. Common causes include departmental tools (different departments use separate software systems that lack integration), legacy systems, and no central data architecture.  Example: Sales and marketing teams using different CRMs that do not share customer data. Sales may be unaware of recent marketing interactions, leading to missed opportunities or duplicated efforts. Business impact: Teams work with partial data, making decisions based on incomplete picture. Employees waste time compiling data from multiple sources. Silos lead to inefficiencies and errors when teams cannot access each other's data. Solution: Use tools like Fivetran or Talend to connect disparate systems. Implement Customer Data Platform (CDP) or data lake to unify data from all departments. 8. Validation FailuresValidation failures occur when data does not meet predefined business rules or criteria. This can lead to corrupted records or incorrect data being entered into the system. Common causes include weak data validation logic (insufficient or absent rules to check data for accuracy, completeness, or format) and inconsistent rule enforcement (validation rules not consistently applied across all data entry points). Example: Revenue field containing negative number when it should always be positive. This could disrupt financial reporting or result in inaccurate sales forecasts. Business impact: Invalid data gets stored, which can break workflows, reports, or analytics. When validation fails, downstream systems or processes may fail as they rely on accurate inputs. Invalid or corrupted data skews reports, reducing trust in analytics. Solution: Define validation rules at database level to enforce correct data formats and business logic. Apply checks during data entry, API ingestion, or ETL processes to catch issues early. Set up automated alerts for failed validations. 9. Schema DriftSchema drift occurs when there are unexpected changes in data structure over time. These changes can disrupt data pipelines and analytics if they are not properly managed or documented. Common causes include unannounced updates to APIs (changes in structure of external APIs not communicated to downstream teams), pipeline or schema updates without versioning, and lack of data governance. Example: New column was added to API payload without documentation. If column is not accounted for in ETL process, it could cause pipeline failures or incorrect data processing. Business impact: Data extraction, transformation, and loading (ETL) processes fail when structure of incoming data changes unexpectedly. Schema changes can cause dashboards or reports to break, resulting in misleading insights or lack of reporting. Solution: Use tools like Monte Carlo or Databand to track and alert teams to any changes in schema that could affect data pipelines. Establish versioning and clear documentation for all schema changes. Set up automated schema validation checks. 10. Ambiguous DataAmbiguous data lacks clarity, precise definitions, or much-needed context, making it difficult or impossible to understand and interpret clearly. Typically, ambiguous data occurs due to poor or absent standardization, vague data entries, or inadequate metadata. Example: Data fields labeled only as "value" or "score," data entries noted to be "Pending" with no additional timing information, and acronyms used without being defined. Business impact: Cross-departmental misunderstandings, flawed analysis, inaccurate or shallow reporting, inconsistencies or errors within integrated systems. Solution: Data contracts crystallize definitions and context for data fields unique to an organization. The result furthers data clarity and usability within the org, ensuring data is both easily understood and correctly interpreted. 11. Hidden and Dark DataData professionals use hidden data and dark data interchangeably, though they are slightly different concepts. Hidden data refers to information overlooked or inaccessible within existing data management system. Dark data refers to data that is collected, processed, and stored but remains unutilized. Examples include dormant customer data, unused log files, archived emails, historical transaction data, and sensor data from Internet of Things (IoT). Business impact: Hidden data can lead to increased costs, inefficient data utilization, data siloing, and compliance issues. Dark data results in wasted resources, missed insights, security issues, and data management complexities. Solution: Well-drafted data contracts outline data management and usage protocols, ensuring that all data an organization collects is easily discoverable, usable, and utilized effectively. 12. Poor Data GovernanceGetting serious about data quality requires a clear governance framework and defined data stewardship roles. Without clear governance policies, organizations lack defined standards for data accuracy, ownership, and validation. Teams may follow different rules, or none at all, resulting in inconsistent definitions of "clean" data. Over time, errors go unnoticed, leading to unreliable insights and increased operational or compliance risks. Business impact: Even when CRM data looks clean on the surface, it often is not strong enough to support the kinds of financial decisions leadership actually care about. This gap shows up as suboptimal pricing, missed expansion opportunities, and avoidable churn. Solution: A data governance framework should include policies for data access, usage and compliance; processes for collecting, entering, validating and updating data; metrics for measuring quality; tools used to store, enrich, integrate and monitor data; and people responsible for maintaining data quality. 13. Lack of Data IntegrityData quality is about whether a record is fit for use, while data integrity is about whether that data remains reliable as it moves across systems, workflows and teams. A correctly formatted email address may pass data quality check. But if that email is attached to wrong account in CRM because of broken sync or poor field mapping, you have data integrity problem. The record looks clean, but structure beneath it is unreliable. Business impact: This kind of issue can quietly damage lead routing, attribution, reporting and forecasting. A sync can break, a field can map incorrectly, a duplicate can spread across systems, or a record can be updated in one platform but remain stale in another. Solution: Monitor integration health, validate field mapping across systems, and set up sync health checks. Revenue teams need both quality data and data integrity to build a trustworthy operating model. The AI Risk Multiplier The importance of quality data has increased further as AI becomes embedded in GTM execution. If underlying records are inaccurate, stale or incomplete, AI-driven workflows will produce unreliable outputs faster and at greater scale. This creates several risks: Hallucinated personalization: AI-generated outreach based on bad data can reference wrong job title, company, industry or business context. That damages prospect's trust and weakens your sender reputation. Misaligned lead scoring: When CRM records contain gaps, duplicates or outdated firmographics, AI scoring models can prioritize wrong accounts. Sales teams are then directed towards low-fit prospects while high-value opportunities receive too little attention. Flawed forecasting: AI-driven pipeline predictions rely on quality of contact, account and opportunity data beneath them. If that data is incomplete or inaccurate, revenue forecasts become less reliable, and resource allocation decisions become harder to defend. How to Fix Data Quality IssuesOrganizations can see early improvements within weeks by implementing quick fixes like deduplication and validation. However, long-term results, such as automation and cultural alignment, typically take 6 to 12 months to fully implement. Define clear data standards and ownership. Create data dictionary that includes all data definitions, formats, and standards. Assign data ownership to specific individuals or teams for different types of data. Establish data governance protocols with clear RACI model. Implement automated validation rules. Set up automated checks during ETL processes to validate incoming data before it is ingested into your system. Integrate automated alerts for failed validations. Conduct regular data cleansing and enrichment. Schedule regular data cleansing jobs to identify and remove duplicates, correct formatting issues, and standardize data across systems. Use enrichment APIs to fill in missing or incomplete data. Establish data quality dashboard. Build dashboard using tools like Power BI, Tableau, or Superset to track and visualize metrics in real-time. Set up alerts for thresholds to quickly address potential issues before they escalate. Standardize data entry processes. Create standardized protocols for data entry by defining which fields must be completed, how values should be formatted and which naming conventions teams should use. Integrate data sources. Review how data moves between systems and pay particular attention to similar fields that come from different sources. Use "overwrite existing" or "update existing" rules instead of creating new records automatically. Centralize GTM data where possible. A centralized data layer provides revenue teams with a shared view of accounts, contacts, and markets. It helps sales and marketing coordinate activity and improves reporting accuracy. Train employees on data standards. Human error is a common cause of poor data quality, but it is often a process problem rather than an individual failure. Training should include standard operating procedures, examples of how poor data quality affects revenue, and guidance on compliance requirements. Implement continuous monitoring. Monthly data health reporting is more useful than occasional manual data quality audits because it helps RevOps identify decay before it becomes a revenue problem. For B2B sales teams working with contact data, Whistle provides training frameworks that teach SDRs how to work with the data they have while identifying quality issues that need escalation. Our approach emphasizes understanding that data quality is not just a RevOps problem but a shared responsibility across revenue teams. We train SDRs to recognize when contact information is outdated (prospect mentions they changed roles), when data is incomplete (missing direct dial or mobile number preventing outreach), when records may be duplicated (prospect mentions they already spoke with someone from your team), and when validation is needed (email bounces or phone numbers disconnect). Training teams to spot data quality issues during execution creates a feedback loop that helps RevOps teams prioritize fixes based on real-world impact rather than theoretical concerns, ensuring that data quality efforts focus on what actually prevents revenue rather than what looks messy in a dashboard. Explore more from our blogUnlock the B2B sales playbooks, outreach strategies, and closing techniques we’ve refined across more than 1,000 successful campaigns. Not Sure Which Service Is Right for You?Let’s figure it out together. Book a quick call and we’ll walk you through the best-fit options based on your goals, team structure, and current setup. Latest posts Demo contentInterviews, tips, guides, industry best practices, and news.  UX review presentationsHow do you create compelling presentations that wow your colleagues and impress your managers? Read post  Migrating to Linear 101Linear helps streamline software projects, sprints, tasks, and bug tracking. Here’s how to get started. Read post  Building your API StackThe rise of RESTful APIs has been met by a rise in tools for creating, testing, and managing them. Read post |



